
Age
print('제일 나이 많은 탑승객 : {:.1f} years'.format(df_train['Age'].max()))
print('제일 어린 탑승객 : {:.1f} years'.format(df_train['Age'].min()))
print('탑승객 평균 나이 : {:.1f} years'.format(df_train['Age'].mean()))제일 나이 많은 탑승객 : 80.0 years
제일 어린 탑승객 : 0.4 years
탑승객 평균 나이 : 29.7 years
📌 커널 밀도 추정 검색해서 알아보기
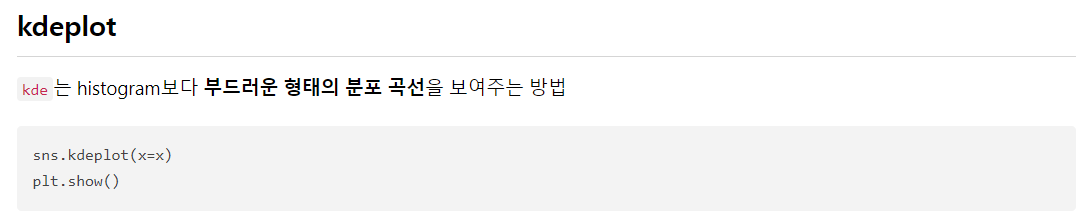
fig, ax = plt.subplots(1, 1, figsize=(9,5))
sns.kdeplot(df_train[df_train['Survived']==1]['Age'],ax=ax)
sns.kdeplot(df_train[df_train['Survived']==0]['Age'],ax=ax)
plt.legend(['Survived==1','Survived==0'])
plt.show()
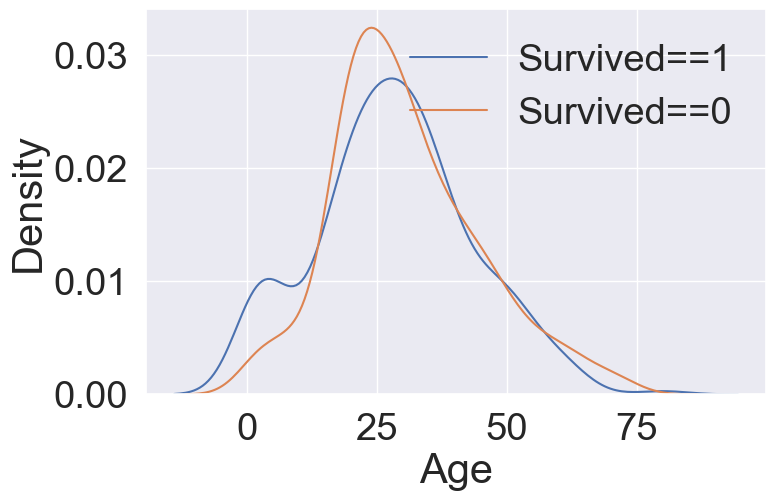
↑ 아래의 히스토그램을 부드러운 형태의 분포 곡선을 보여주는 방법이 ↑kdeplot↑이라는 것을 알 수 있다.
df_train[df_train['Survived']==1]['Age'].hist()
df_train[df_train['Survived']==0]['Age'].hist()
plt.legend(['Survived==1','Survived==0'])
plt.show()
📌 도화지를 준비하는 3가지 방법.
f = plt.figure(figsize=(10,10))f, ax = plt.subplots(1, 1, figsize =(10,10))
# ax.plot() / ax.set_xlable('sdf') x레이블을 넣어주는 방법.plt.figure(fisize=(10,10))
📌 클래스 내 연령 분포 => 생존에 대한 정보가 없다.
plt.figure(figsize=(8,6))
df_train['Age'][df_train['Pclass']==1].plot(kind='kde')
df_train['Age'][df_train['Pclass']==2].plot(kind='kde')
df_train['Age'][df_train['Pclass']==3].plot(kind='kde')
plt.xlabel('Age')
plt.title('Age Distribution within classes')
plt.legend(['1st Class','2nd Class','3nd Class'])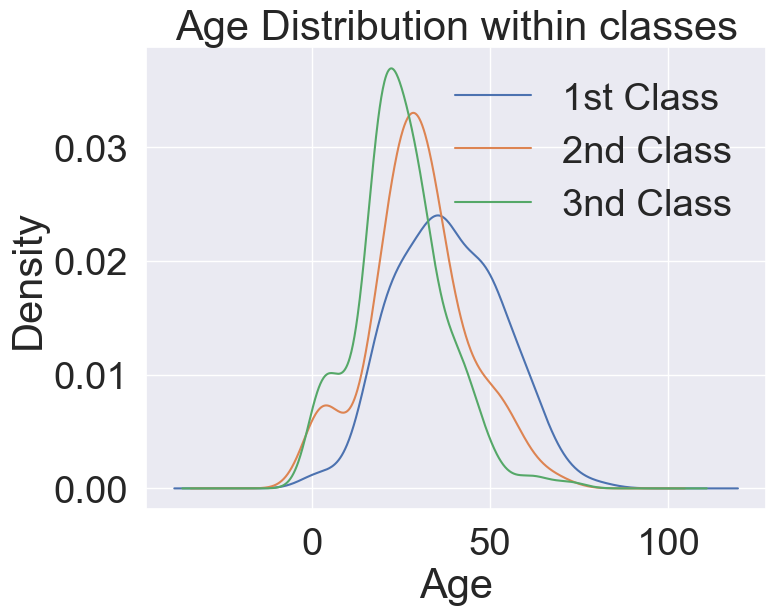
📌 생존에 따른 pcalss와 age 정보
fig, ax= plt.subplots(1,1,figsize=(9,5))
sns.kdeplot(df_train[(df_train['Survived']==0) & (df_train['Pclass']==1)]['Age'],ax=ax)
sns.kdeplot(df_train[(df_train['Survived']==1) & (df_train['Pclass']==1)]['Age'],ax=ax)
plt.title('1st class')
plt.legend(['Survived==1','Survived == 0'])
plt.show()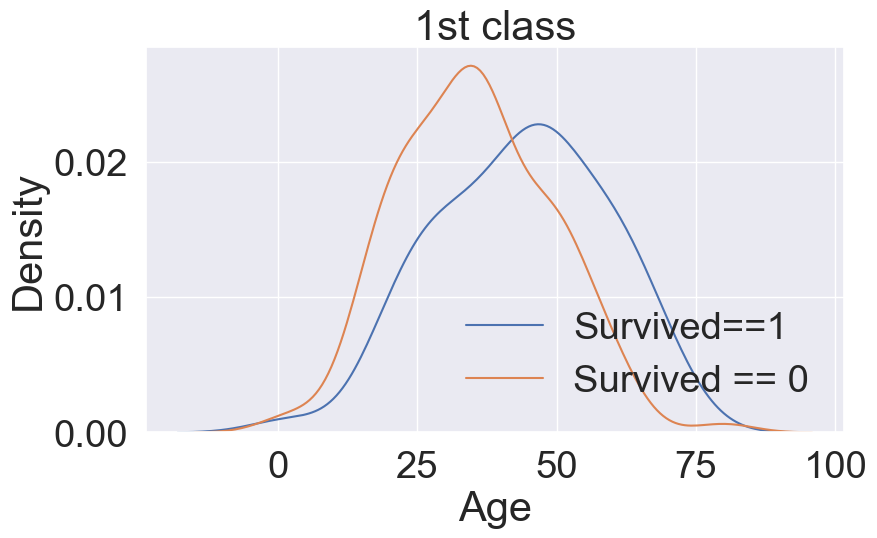
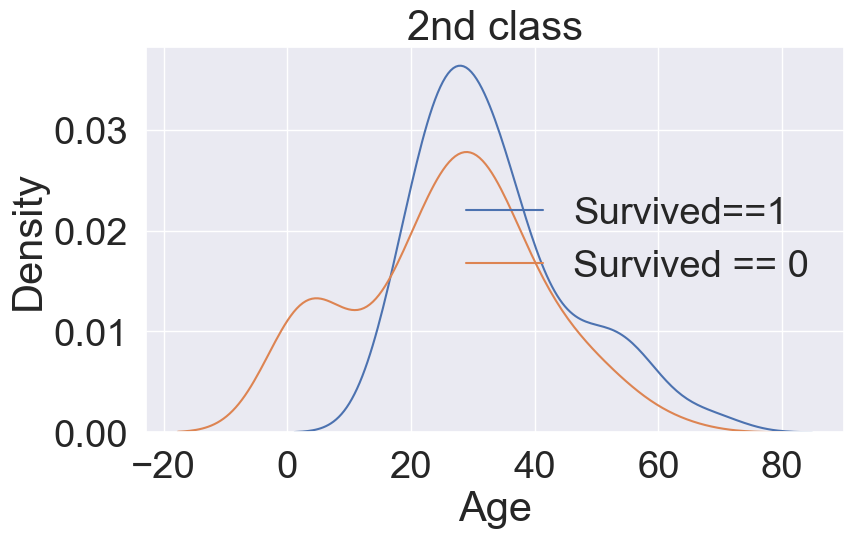

- 2nd class와 마찬가지로 3rd 또한 젊은 사람들의 생존율이 높은 것을 볼 수 있다.
📌 반복문을 이용한 Age에 따른 생존율
change_age_range_survival_ratio = []
for i in range(1,80):
change_age_range_survival_ratio.append(df_train[df_train['Age']<i]['Survived'].sum()/len(df_train[df_train['Age']<i]['Survived']))
plt.figure(figsize=(7,7))
plt.plot(change_age_range_survival_ratio)
plt.title('Survival rate change depending on range of Age', y = 1.02)
plt.ylabel('Survival rate')
plt.xlabel('Range of Age(0~x)')
plt.show()
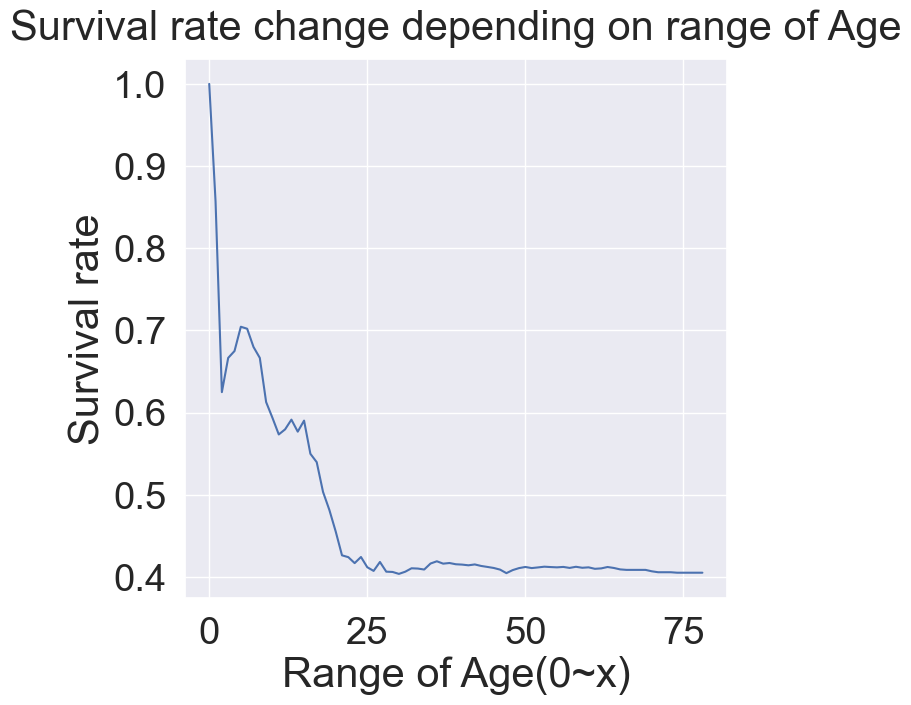
💡 len(df_train[df_train['Age']<i]['Survived'])과 df_train[df_train['Age']<i]['Survived'].shape은 같은 값을 도출해낸다.
💡 df_train[df_train['Age']<i]['Survived'].sum() / len(df_train[df_train['Age']<i]['Survived'])
=> 생존인원 수의 총합 / 변량의 개수로 나눈 것들 중 Survived열만 추출한 것을 의미
💡나이가 어릴수록 생존확률이 확실히 높다는 것을 시각화를 통해 확인할 수 있다.
'Study > kaggle' 카테고리의 다른 글
| 캐글 타이타닉 Titanic - 6. EDA - Embarked (0) | 2023.03.11 |
|---|---|
| 캐글 타이타닉 Titanic - 5. Age, Sex, Pclass (violinplot) (0) | 2023.03.11 |
| 캐글 타이타닉 Titanic - 3. EDA - Sex(성별) (0) | 2023.03.08 |
| 캐글 타이타닉 Titanic 2. EDA-Pclass (0) | 2023.03.08 |
| 캐글 타이타닉 Titanic 1. Dataset check (0) | 2023.03.06 |